Dialectizer is a simple (and silly) descendant of BaseHTMLProcessor. It runs blocks of text through a series of substitutions, but it makes sure that anything within a <pre>...</pre> block passes through unaltered.
To handle the <pre> blocks, we define two methods in Dialectizer: start_pre and end_pre.
Example 4.16. Handling specific tags
def start_pre(self, attrs): 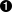 self.verbatim += 1
self.verbatim += 1 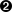 self.unknown_starttag("pre", attrs)
self.unknown_starttag("pre", attrs)  def end_pre(self):
def end_pre(self):  self.unknown_endtag("pre")
self.unknown_endtag("pre")  self.verbatim -= 1
self.verbatim -= 1 
| start_pre is called every time SGMLParser finds a <pre> tag in the HTML source. (In a minute, we’ll see exactly how this happens.) The method takes a single parameter, attrs, which contains the attributes of the tag (if any). attrs is a list of key/value tuples, just like unknown_starttag takes. | |
| In the reset method, we initialize a data attribute that serves as a counter for <pre> tags. Every time we hit a <pre> tag, we increment the counter; every time we hit a </pre> tag, we’ll decrement the counter. (We could just use this as a flag and set it to 1 and reset it to 0, but it’s just as easy to do it this way, and this handles the odd (but possible) case of nested <pre> tags.) In a minute, we’ll see how this counter is put to good use. | |
| That’s it, that’s the only special processing we do for <pre> tags. Now we pass the list of attributes along to unknown_starttag so it can do the default processing. | |
| end_pre is called every time SGMLParser finds a </pre> tag. Since end tags can not contain attributes, the method takes no parameters. | |
| First, we want to do the default processing, just like any other end tag. | |
| Second, we decrement our counter to signal that this <pre> block has been closed. |
At this point, it’s worth digging a little further into SGMLParser. I’ve claimed repeatedly (and you’ve taken it on faith so far) that SGMLParser looks for and calls specific methods for each tag, if they exist. For instance, we just saw the definition of start_pre and end_pre to handle <pre> and </pre>. But how does this happen? Well, it’s not magic, it’s just good Python coding.
Example 4.17. SGMLParser
def finish_starttag(self, tag, attrs):
try:
method = getattr(self, 'start_' + tag)
except AttributeError:
try:
method = getattr(self, 'do_' + tag)
except AttributeError:
self.unknown_starttag(tag, attrs)
return -1
else:
self.handle_starttag(tag, method, attrs)
return 0
else:
self.stack.append(tag)
self.handle_starttag(tag, method, attrs)
return 1  def handle_starttag(self, tag, method, attrs):
method(attrs)
def handle_starttag(self, tag, method, attrs):
method(attrs) 
| At this point, SGMLParser has already found a start tag and parsed the attribute list. The only thing left to do is figure out whether there is a specific handler method for this tag, or whether we should fall back on the default method (unknown_starttag). | |
| The “magic” of SGMLParser is nothing more than our old friend, getattr. What you may not have realized before is that getattr will find methods defined in descendants of an object as well as the object itself. Here the object is self, the current instance. So if tag is 'pre', this call to getattr will look for a start_pre method on the current instance, which is an instance of the Dialectizer class. | |
| getattr raises an AttributeError if the method it’s looking for doesn’t exist in the object (or any of its descendants), but that’s okay, because we wrapped the call to getattr inside a try...except block and explicitly caught the AttributeError. | |
| Since we didn’t find a start_xxx method, we’ll also look for a do_xxx method before giving up. This alternate naming scheme is generally used for standalone tags, like <br>, which have no corresponding end tag. But you can use either naming scheme; as you can see, SGMLParser tries both for every tag. (You shouldn’t define both a start_xxx and do_xxx handler method for the same tag, though; only the start_xxx method will get called.) | |
| Another AttributeError, which means that the call to getattr failed with do_xxx. Since we found neither a start_xxx nor a do_xxx method for this tag, we catch the exception and fall back on the default method, unknown_starttag. | |
| Remember, try...except blocks can have an else clause, which is called if no exception is raised during the try...except block. Logically, that means that we did find a do_xxx method for this tag, so we’re going to call it. | |
| By the way, don’t worry about these different return values; in theory they mean something, but they’re never actually used. Don’t worry about the self.stack.append(tag) either; SGMLParser keeps track internally of whether your start tags are balanced by appropriate end tags, but it doesn’t do anything with this information either. In theory, you could use this module to validate that your tags were fully balanced, but it’s probably not worth it, and it’s beyond the scope of this chapter. We have better things to worry about right now. | |
| start_xxx and do_xxx methods are not called directly; the tag, method, and attributes are passed to this function, handle_starttag, so that descendants can override it and change the way all start tags are dispatched. We don’t do need that level of control, so we just let this method do its thing, which is to call the method (start_xxx or do_xxx) with the list of attributes. Remember, method is a function, returned from getattr, and functions are objects. (I know you’re getting tired of hearing it, and I promise I’ll stop saying it as soon as we stop finding new ways of using it to our advantage.) Here, the function object is passed into this dispatch method as an argument, and this method turns around and calls the function. At this point, we don’t have to know what the function is, what it’s named, or where it’s defined; the only thing we have to know about the function is that it is called with one argument, attrs. |
Now back to our regularly scheduled program: Dialectizer. When we left, we were in the process of defining specific handler methods for <pre> and </pre> tags. There’s only one thing left to do, and that is to process text blocks with our pre-defined substitutions. For that, we need to override the handle_data method.
Example 4.18. Overriding the handle_data method
def handle_data(self, text):
self.pieces.append(self.verbatim and text or self.process(text)) | handle_data is called with only one argument, the text to process. | |
| In the ancestor BaseHTMLProcessor, the handle_data method simply appended the text to the output buffer, self.pieces. Here the logic is only slightly more complicated. If we’re in the middle of a <pre>...</pre> block, self.verbatim will be some value greater than 0, and we want to put the text in the output buffer unaltered. Otherwise, we will call a separate method to process the substitutions, then put the result of that into the output buffer. In Python, this is a one-liner, using the and-or trick. |
We’re close to completely understanding Dialectizer. The only missing link is the nature of the text substitutions themselves. If you know any Perl, you know that when complex text substitutions are required, the only real solution is regular expressions.